Introducing CollegeScan
Mar 01, 2016
A Client for the College Scorecard API
Today I am excited to introduce collegeScan - a Client for the College Scorecard. This is my first published app since HakkerJobs and while it has been great to publish updates to those apps I am really happy about being able to launch a whole new app. I am excited to tell you more in this post.
The Idea
The idea came to me as I was playing around with the data.gov site. The first iteration of what would become collegeScan was some sort of elementary school tracker - a parent would be able to track the schools around their particular area. However what became clear was that the data for elementary schools was very fragmented. It is on a state by state basis and it is locked up in weird formats like tab delineated text files. To me, I realized that I would have to spend a lot of time working on just cleaning the data - and that felt to me not worth the time.
However while in the midst of the research, I came across the College Scorecard. Basically the government released about 20 years worth of data on colleges - the cost of them as well as their admissions data - with the goal of making the college selection process easier. Check out their technical paper for the whole story.
This information, just released in late 2015, seemed to me worth sharing with other people. I created a new project on xCode and rolled up my sleeves.
The Implementation
collegeScan is an evolution of the work I did on HakkerJobs with a lot of the improved tools that I worked on from other apps since then. They are both similar in that they are tabbed apps with each tab containing tableviews. There are similar features - saving certain items, browsing, and such. However, there are big improvements made when it came to getting, parsing, and presenting large amounts of information.
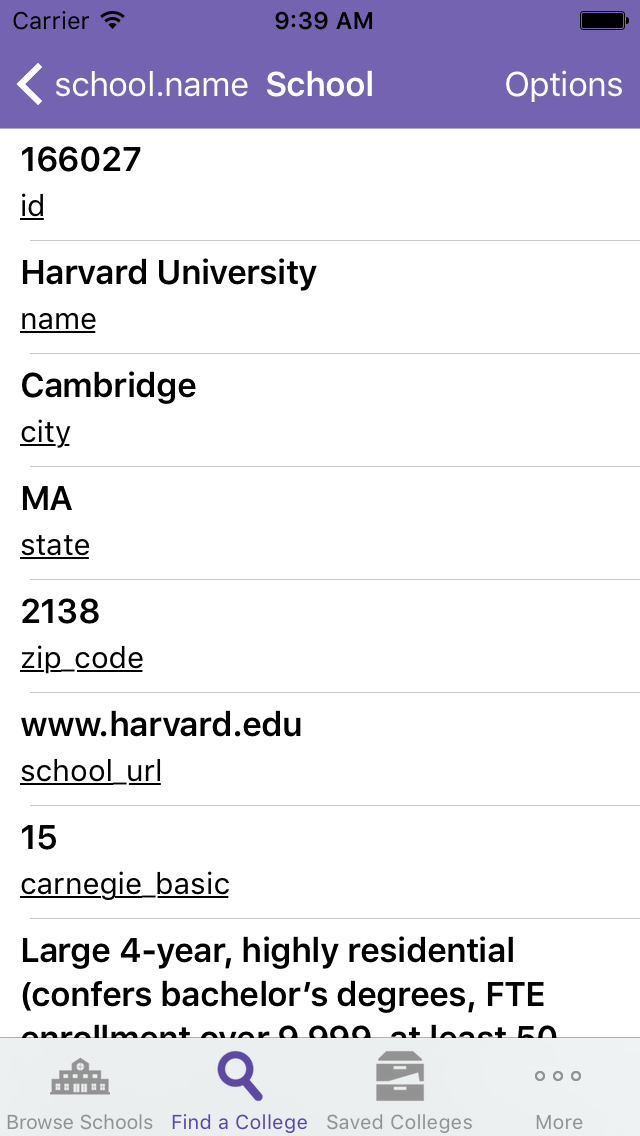
Whereas HakkerJobs uses multi-threading in order to download a lot of HN threads, collegeScan only has to make one API call. However the data that came back was large and deeply nested. Often the format would look something like this:
{
metadata: {
total: 16,
page: 0,
per_page: 20
},
results: [
{
id: 447801,
school.name: "University of East-West Medicine",
school.zip: 94085
},
{
id: 459213,
school.name: "Gurnick Academy of Medical Arts",
school.zip: 94403
},
Within the results array would be a deeply nested JSON object. The data schema of the CollegeScorecard data was something like:
[year][type of data (like available academic program)][Detail]
Such a deep nested object made parsing a pain. I adopted ObjectMapper while building a previous project (a Reddit client that never got off the ground) and ported a lot of the learnings I had there to this. collegeScan uses ObjectMapper to map a large amount of data as well as a nifty feature (custom transformations) to help format that raw data.
For the UI, I went back to the Reddit Client (named LurkFish) and lifted a lot of the work that I did with AsyncDisplayKit. Check out the blog post that I wrote about taking ASDK to Hakkerjobs.
collegeScan’s inner guts works based on a Reddit client that I like to use (Antenna). A viewcontroller is tied to a school (or a type of query, the API call is basically the same). It is initialized with the necessary characteristics, customizes its correct query params and fires off for the data. Once the data is received and correctly parsed, it calls upon a number of a helper to parse and present the data. This data holds the dictionary of the API, something that took a lot of time to actually put together from the various documentation that I have found lying around.
The app also implements a lot of the new concepts that I have learned since HakkerJobs. There is the use of a Mirror to reflect and iterate on the various internal variables of the school data object (since each data table needs to have a label to explain the value). It also uses key-value to help make that job easier. There is an improved error handling system within the app - more guards and lets.
What’s Next
From the first commit to the time I submitted to the Store was about 16 days, but I had worked on it pretty much every day. Even with that being said, it is a really pleasant change of pace compared to the aforementioned Reddit client - which I had worked on for over a month and still seemingly months away from a first deploy. While waiting for the first iteration of collegeScan to get approved on the store, I began work on a big new feature that I really wanted to get done: A comparison between two different colleges.
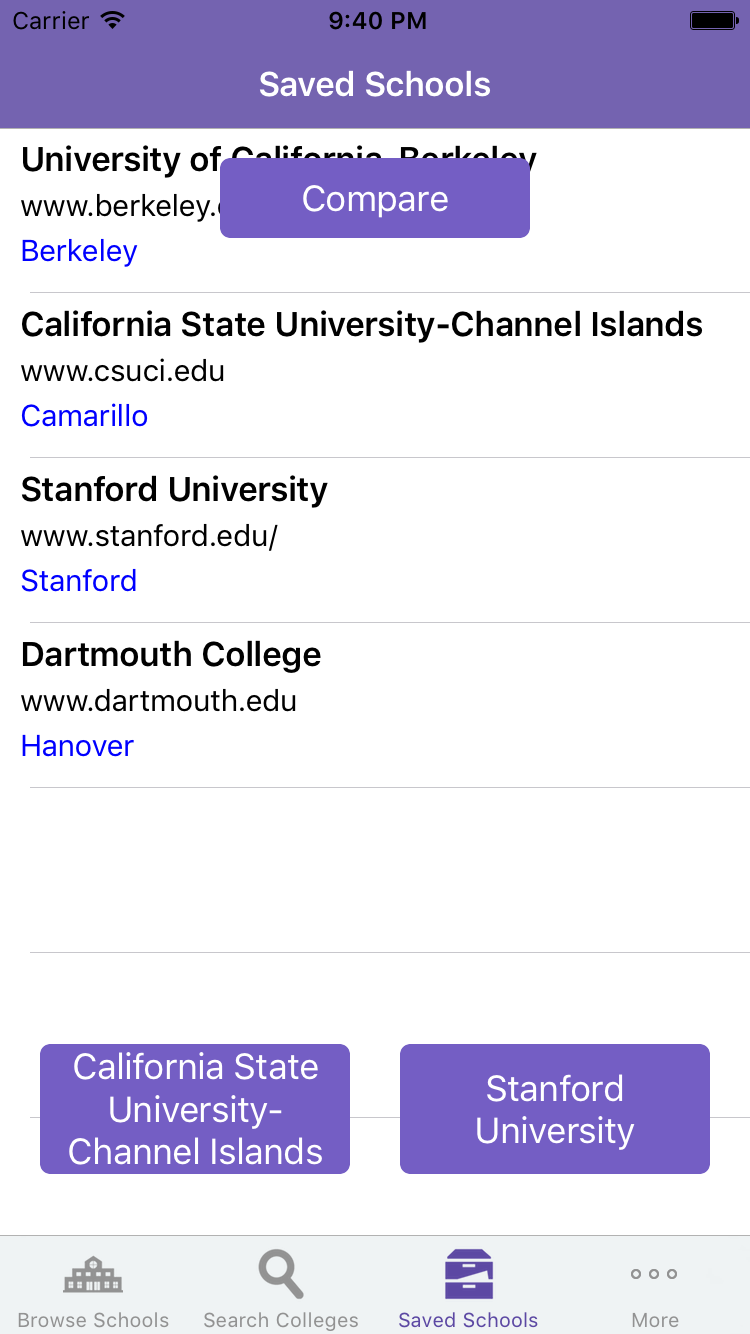
There remains some work that need be done on the screens but I think I’ll be ready to push this new update shortly.
I am excited about this app. I think it has some great uses and I am always pleased to look up my alma mater on it.
Share